-----------------------------------------------欢迎查看网络安全连载博客-----------------------------------
---------------------------------------------------------------------------------------------------------------------本文绝大部分内容来自《网络安全基础——应用与标准》第五版——清华大学出版社。
当中蓝色部门是自己加入
安全散列函数
单向散列函数或者安全散列函数之所以重要,不仅在于消息认证(消息摘要。数据指纹)。还有数字签名(加强版的消息认证)和验证数据的完整性。常见的单向散列函数有MD5和SHA
散列函数的要求
散列函数的目的是文件、消息或者其它数据块产生“指纹”。为满足在消息认证中的应用,散列函数H必须具有下列性质:
(1)H可适用于随意长度的数据块。
(2)H能够生成固定长度的输出。
(2)对于随意给定的x,计算H(x)相对easy,而且能够用软/硬件实现。
(4)对于随意给定的h,找到满足H(x)=h的x在计算上不可行。满足这一特性的散列函数称之为:具备抗原像攻击性。
(5)对于随意给定的数据块x,找到满足H(y)=H(x)的y ≠ x在计算上是不可行;满足这一特性的散列函数称之为:抗弱碰撞性。
(6)找到满足H(x) = H(y)的随意一对(x,y)在计算上是不可行的。
满足这一特性的散列函数称之为:抗碰撞性。
前三个性质是使用散列函数进行消息认证的实际可行要求。第四个属性,抗原像攻击,防止攻击者能够回复秘密值。抗弱碰撞性保证了对于给定的消息。不可能找到具有同样散列值的可替换消息。
满足上面前5个性质的散列函数称之为弱散列函数。
假设还满足第6个性质则称之为强散列函数。
一般来说:能够认识散列函数的两个特点就OK,1.输出固定长度的 2. 不可逆转!
散列函数的安全性
有两种方法能够攻击安全散列函数:password分析法和暴力攻击法。
散列函数抵抗暴力攻击的强度全然依赖于算法生成的散列码长度。
Van Oorschot和Wiener以前提出,花费1000万美元涉及一个被专门用来搜索MD5算法碰撞的机器,则平均24天内就能够找到一个碰撞。
2004年8月中国password学家王小云教授等首次发布了提出一种寻找MD5碰撞的新方法。眼下利用该方法用普通微机几分钟内就可以找到MD5的碰撞。MD5已经呗彻底攻破。
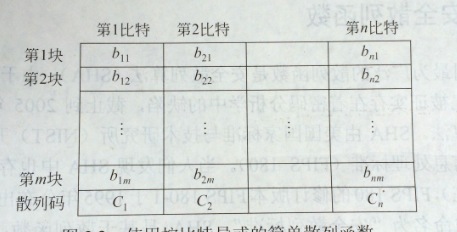
简单散列函数
例如以下所看到的
Ci = bi1⊕ bi2⊕ … ⊕ bim
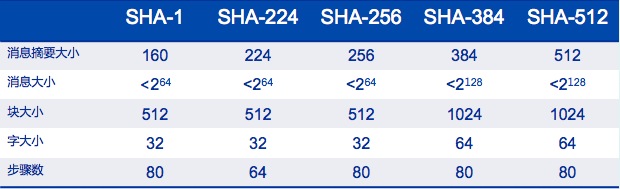
SHA安全散列函数
由于其它每一种被广泛应用的散列函数都已经被证实存在这password分析学中的缺陷。接着到2005年,SHA也许仅存的安全散列算法。SHA由美国国家标准与技术研究院(NIST)开发。
如图所看到的:
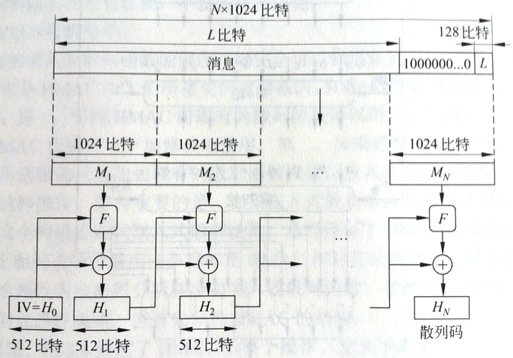
● 第1步、追加填充比特
● 第2步、追加长度
● 第3步、初始化散列缓冲区
这些字的获取方式例如以下:前8个素数取平方跟,取小数部分前64位。
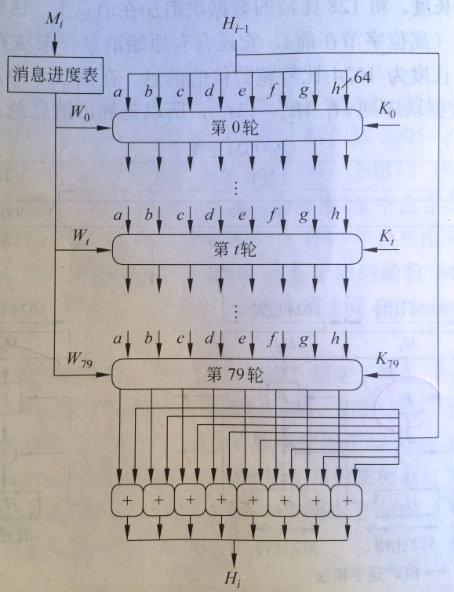
● 第4步、处理1024比特的数据块消息
该模块在上图中标记为F,下图是其逻辑关系。每一轮都以512比特的缓冲区值abcdefgh作为输入。而且更新缓冲区内容。
在第一轮时,缓冲区的值是中间值Hi-1.在随意t轮。使用从当前正在处理的1024比特的数据块(Mi)导出64位比特值Wt。每一轮还使用附加常数Kt。当中0<=t<=79表示80轮中的某一轮。这些常数的获取方式例如以下:前8个素数的立方根。取小数部分的前64位。这些常数提供了64位随机串集合,能够初步消除输入数据中的不论什么规则性。第80轮输出加到第1轮输入(Hi-1)生成Hi。
缓冲区里的8个字与Hi-1中对应的字进行模264加法运算。